まんがタイムきららMAXの掲載順を可視化・分析する2020
 ↑今回の成果
↑今回の成果
はじめに
この記事は過去に書いたどうびじゅの連載終了が告知され心と胃を痛めているきららmax読者のためのスクレイピングを使ったデータ収集と考察のススメ - Qiitaのリバイバル版です。
もうこの記事から1年経っているので新しくデータを集めて可視化しようかなと。
毎年一回はやりたいなこれ。(気に入ってる)
キャラット版はこちら (まだ作ってない) 作った
データの収集
なんと書いた本人がやり方を全く覚えていません。
結局自分が書いた記事を読む羽目に。(技術者あるある)
解説は上の記事でやったのでやりません。(無情) と思ったけど書き直したのでやっぱちょっとやる。
この記事を見てやってみたいって思った人がいたら、やり方とか注意事項とか書いてあるので最初に貼ったリンクを読んでね。
環境
実行環境はこちら。
$ uname -a
Linux kali 4.18.0-kali2-amd64 #1 SMP Debian 4.18.10-2kali1 (2018-10-09) x86_64 GNU/Linux
$ python3 --version
Python 3.7.6
$ pip3 show requests
Name: requests
Version: 2.22.0
$ pip3 show beautifulsoup4
Name: beautifulsoup4
Version: 4.8.2
$ pip3 show matplotlib
Name: matplotlib
Version: 3.1.2
$ pip3 show numpy
Name: numpy
Version: 1.17.4
$ pip3 show chardet
Name: chardet
Version: 3.0.4
データの収集・可視化
とりあえず、自分の過去の記事を見ながらプログラムを修正することに。
目を覆いたくなるような残念なコードですが耐えながら読みます。
前回から変えた部分は、
- 同じことを何回も書いている部分があるのでオブジェクト化
- 掲載順が下がっているのかセンターカラーの定位置なのかわからなかったのでセンターカラーのときは印をつけた
- 今までfontタグを使って掲載順を判断していたが余計な文章が増えていたので
<font color="8000FF">で囲われた部分だけを採用するようにした
のだいたい3つです。
ちょっとずつサイトが変わっているので変えなくちゃいけない(めんどくさい)
使用したプログラムは以下。
#-*-coding:utf-8 -*-
import re
import regex
import sys
import requests
import collections
from bs4 import BeautifulSoup
from time import sleep
import numpy as np
import matplotlib.pyplot as plt
month_list=['Jan.','Feb.','Mar.','Apr.','May','June','July','Aug.','Sept.','Oct.','Nov.','Dec.'];
mid_list=['642', '646', '650', '654', '658', '662', '666', '670', '674', '678', '682', '686', '690', '694', '698', '702']
bottom=24
mid=187
year=2019
month=1
index=0
center_colors=[]
center_color_all=[]
count_cc={}
date_list=[]
date_place=[]
class Article:
def __init__(self,_label,_keyword):
self.label=_label
self.keyword=_keyword
self.list=[]
self.center_list=[]
self.mark_point=[]
def is_centercolor(self,center_colors):
flag=False
for cc in center_colors:
if self.keyword in cc:
flag=True
break
if flag:
self.mark_point.append(len(self.center_list))
self.center_list.append(flag)
Article_list=[ Article("bozaro","ぼっち"),
Article("syachiku","社畜さん"),
Article("umirie","旅する海と"),
Article("kinmoza","きんいろ"),
Article("gochiusa","ご注文は"),
Article("comic_girls","こみっくが"),
Article("stella","ステラのまほう")]
while index < len(mid_list):
print ("\n{}年{}月号".format(year,month))
date_list.append(str(year)+"\n"+month_list[month-1]);
date_place.append(index)
url='http://www.dokidokivisual.com/magazine/max/book/index.php?mid={0}'.format(mid_list[index])
html=requests.get(url)
source=BeautifulSoup(html.content,"html.parser")
strongs=source.find_all("strong")
center_colors=[]
for i in range(0,len(strongs),2):
_result=re.search('センターカラー|巻頭カラー',strongs[i].text)
if _result!= None:
center_colors.append(re.search('『.+』',strongs[i+1].text).group())
center_color_all.append(center_colors[-1])
print(center_colors)
span=source.find_all("font",color="#8000FF")
i=0
for tag in span:
try:
i+=1
name=tag.string
print(i,name)
for art in Article_list:
if art.keyword in name and len(art.list)==index:
art.list.append(i)
art.is_centercolor(center_colors)
except:
pass
for art in Article_list:
if len(art.list)==index:
art.list.append(None)
index+=1
if month==12:
year+=1
month=1
else:
month+=1
sleep(1)
print(collections.Counter(center_color_all))
for art in Article_list:
print(art.center_list)
print(art.mark_point)
X_list=list(range(len(mid_list)))
plt.xlabel('Publication issue')
plt.ylabel('Publication order')
plt.title('Changes in the order of publication')
for art in Article_list:
plt.plot(X_list, art.list, '.', linestyle='solid', marker="D", markevery=art.mark_point ,label=art.label)
plt.gca().invert_yaxis()
plt.grid(color='gray')
plt.legend(bbox_to_anchor=(1.02,1),loc='upper left',borderaxespad=0)
plt.subplots_adjust(right=0.7)
plt.xticks(date_place,date_list)
plt.yticks(range(1,bottom))
plt.show()
こんな感じ。
前回に比べてだいぶコードがスッキリしました。
任意のところにだけプロットするのが大変だった。(小並感)
ちなみにスクレイピングするときにURLが必要でhttp://www.dokidokivisual.com/magazine/max/book/index.php?mid=654のように
midなるものが必要なのだがこれは予め取得して配列に格納することにしてる。
いちいち取りに行くのは無駄だし、サーバに負荷がかかるのでよろしくない。
midを取りに行くコードはこちら。
#-*-coding:utf-8 -*-
import sys
import requests
import re
from bs4 import BeautifulSoup
from time import sleep
year=2019
mid_list=[]
while year<=2020:
print ("\n{}年".format(year))
url='http://www.dokidokivisual.com/magazine/max/backnumber/index.php?y={0}'.format(year)
html=requests.get(url)
source=BeautifulSoup(html.content,"html.parser")
a=source.find_all("a")
i=0
for tag in a:
try:
if "mid" in tag['href']:
print(tag['href'])
print(re.search("\d*$",tag['href']).group(0))
mid_list.append(re.search("\d*$",tag['href']).group(0))
except:
pass
year+=1
mid_list=list(set(mid_list))
sleep(1)
mid_list.sort()
print(mid_list)
一応、githubにも上げておく。
結果
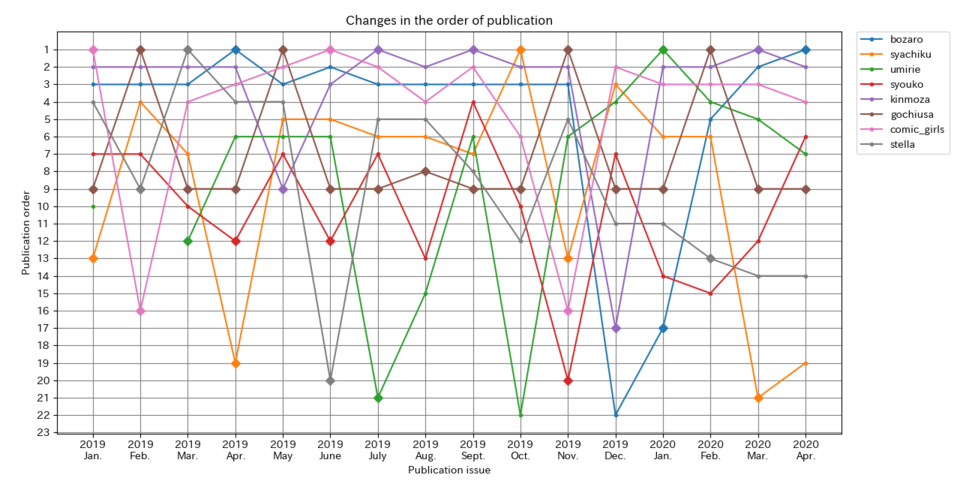
上記のプログラムを実行した結果がこちら。
縦軸は掲載順、横軸は月です。
ダイヤモンドがついているところはカラーページのときです。
カラーページのときは掲載位置が固定されるのでこのような形になります。
ちなみに選出した作品は僕の趣味で選出しました。
全部のデータを取得しているので全部表示してもいいんですが、読み切りも入っちゃうし何よりごちゃごちゃになっちゃうのでやめました。
せっかくセンターカラー数の取得もできたので出力してみました。
Counter({ ‘『ご注文はうさぎですか?』': 16,
‘『社畜さんと家出少女』': 5,
‘『きんいろモザイク』': 5,
‘『こみっくがーるず』': 4,
‘『ステラのまほう』': 4,
‘『エンとゆかり』': 4,
‘『ななどなどなど』': 4,
‘『旅する海とアトリエ』': 3,
‘『しょうこセンセイ!』': 3,
‘『いのち短し善せよ乙女』': 3,
‘『魔王城ツアーへようこそ!』': 2,
‘『ぼっち・ざ・ろっく!』': 2,
‘『委員長のノゾミ』': 2,
‘『私を球場に連れてって!』': 2,
‘『みわくの魔かぞく』': 2,
‘『ハルメタルドールズ』': 2,
‘『六条さんのアトリビュート』': 2,
‘『初恋*れ〜るとりっぷ』': 2,
‘『ホレンテ島の魔法使い』': 2,
‘『ももいろジャンキー』': 1,
‘『タベモノガタリ』': 1,
‘『たつのお年頃』': 1,
‘『魔王と勇者が百合結婚するお話。』': 1,
‘『ハルメタルドールズ!』': 1,
‘『初恋*れ~るとりっぷ』': 1,
‘『吸血鬼さんと行く∞日の終末旅行』': 1,
‘『ほーぷす×ハウス』': 1,
‘『月が綺麗だから盗んで』': 1,
‘『ぬるめた』': 1,
‘『ぼっち・ざ・ろっく!』': 1})
一見いい感じなんですがサイトでの表記にブレがあるので正確じゃありません…
例えば『ぼっち・ざ・ろっく!』と『ぼっち・ざ・ろっく!』という風に全角の!と半角の!が混在していて上手く判定できず、本来3回なのに2つに別れてしまってします。
ここは改善点です。
現実的な対策は表記ゆれしそうな記号をすべて排除してから評価するとかですかね…
考察
この結果を見て驚くべきはごちうさの驚異のセンターカラー率。
なんと100%!こんなんじゃkoi先生が過労死してしまう…
そしてさらに驚いたのが社畜さんと家出少女が5回(2位)という記録。きんモザと並びます。
これは表紙ゲットにもうなずけますね…
あと、新しい作品ってイメージがあった作品がもう長いことやっていてびっくりしました。
僕の中ではぼざろはかなり新しいイメージだったのですがもう2巻出ているわけですから2年以上やっているわけですよ。
時の流れは残酷です。
データ面で言えば、センターカラーの位置も微妙に変動してますね。
1年とかで変わるかなとか思ってたけど意外と短いスパンで変わってますね…
多少センターカラーを取得できなくても掲載順から逆算できるでしょ(慢心)とか思ってたけど厳しいかもな…
海リエのセンターカラーに関係なくV字回復している部分(ぼざろにもある)は多分ページ増量に伴って最後に回されるやつかと思われます。(それか2本掲載)
感想
実はこれ、もう一度きららの掲載順の記事を書きたかったのもあるんですけど、きららのデータを集めたサイトを作ろうと考えていてそれの準備運動として作ったんですよね。
都合よくバックナンバーのページにデータはあるので色々データを集めて可視化できるようなサイトをこのブログ内に構築しようかなと。
今回の記事でいい感じにスクレイピングのコツとかは思い出せたのでこれから暇を見つけて構築いていきたいなと思います。
あと、今回のプログラムを流用してキャラット版のデータも準備運動2として作ろう。