まんがタイムきららキャラットの掲載順を可視化・分析する2020
 ↑今回の成果
↑今回の成果
はじめに
この記事はおととい書いた「まんがタイムきららMAXの掲載順を可視化・分析する2020」の続きです。
前回僕はこんなことを言いました。
あと、今回のプログラムを流用してキャラット版のデータも準備運動2として作ろう。
見通しが甘かった…
MAXのやつが意外と綺麗に書けたので浮かれていましたが、キャラットのデータ取得は地獄でした…
特に地獄だったのは、
- MAXは
<font color="8000FF">という非常に都合の良いタグに囲まれていたのでデータの取得がすっごい楽だったのですが、 キャラットは汎用的な<li>で囲われていてデータの特定が難しいものになってました。(絶望) - MAXのページとキャラットのページを見比べてみてください。 今月の見どころの構成が全く違います。なんて恐ろしいのでしょう。センターカラーを取得するところは書き直しになりました。
- 2020年3月号と2020年4月号を 見比べてみてください。3月号は表紙と巻頭カラーの作品が違いますが、4月号は同じ作品が担当しています。つまり項目の数が違うのです…
の3つです。
まぁつまりどういうことかと言うと書いたプログラムを書き換えるだけで取得できるでしょ(慢心)と思っていたら大幅な書き換えが必要な上、地獄のような取得方法が待ち受けていたってやつです。
大変だった…(満身創痍)
使用したプログラム
リポジトリはここ。
とりあえず使用したプログラムを示します。(プログラムに興味ない人は読み飛ばして結果と考察に飛んでください)
#-*-coding:utf-8 -*-
import re
import regex
import sys
import requests
import collections
from bs4 import BeautifulSoup
from time import sleep
import numpy as np
import matplotlib.pyplot as plt
#input get_mid.py result here.
mid_list=['644', '648', '652', '656', '660', '664', '668', '672', '676', '680', '684', '688', '692', '696', '700', '704']
month_list=['Jan.','Feb.','Mar.','Apr.','May','June','July','Aug.','Sept.','Oct.','Nov.','Dec.']
bottom=24
mid=187
year=2019
month=1
index=0
mark_point_x=[]
mark_point_y=[]
mark_point_color=[]
color_cycle = plt.rcParams['axes.prop_cycle'].by_key()['color']
center_colors=[]
center_color_all=[]
count_cc={}
date_list=[]
date_place=[]
class Article:
def __init__(self,_label,_keyword):
self.label=_label
self.keyword=_keyword
self.list=[]
self.center_list=[]
def is_centercolor(self,center_colors):
flag=False
for cc in center_colors:
if self.keyword in cc:
flag=True
break
self.center_list.append(flag)
return flag
Article_list=[ Article("koias","恋する"),
Article("ochifuru","おちこぼれ"),
Article("RPG","不動産"),
Article("killme","キルミー"),
Article("machikado","まちカド"),
Article("Achannel","チャンネル"),
Article("anima","アニマエ"),
Article("NEWGAME","GAME"),
Article("hidameri","ひだまり")]
while index < len(mid_list):
print ("\n{}年{}月号".format(year,month))
date_list.append(str(year)+"\n"+month_list[month-1]);
date_place.append(index)
url='http://www.dokidokivisual.com/magazine/carat/book/index.php?mid={0}'.format(mid_list[index])
html=requests.get(url)
source=BeautifulSoup(html.content,"html.parser")
strongs=source.find_all("strong")
center_colors=[]
info=(source.find_all("div",class_="info"))[1]
strongs=info.find_all("strong")
if re.search('表紙(&|&)巻頭カラー',info.text):
print("both")
start=0
end=5
else:
print("other")
start=1
end=6
for art in strongs[start:end]:
center_colors.append(re.search('「.+」',art.string).group())
center_color_all.append(center_colors[-1])
print(center_colors)
i=0
articles=source.find("ul",class_="lineup").find_all("strong")
for art in articles:
try:
i+=1
name=art.string
print(i,name)
for color_index,art in enumerate(Article_list):
if art.keyword in name and len(art.list)==index:
art.list.append(i)
if art.is_centercolor(center_colors):
mark_point_x.append(index)
mark_point_y.append(i)
mark_point_color.append(color_cycle[color_index])
except:
pass
for art in Article_list:
if len(art.list)==index:
art.list.append(None)
art.center_list.append(None)
index+=1
if month==12:
year+=1
month=1
else:
month+=1
sleep(1)
print(collections.Counter(center_color_all))
for art in Article_list:
print(art.label)
print(art.list)
print(art.center_list)
X_list=list(range(len(mid_list)))
plt.xlabel('Publication issue')
plt.ylabel('Publication order')
plt.title('Changes in the order of publication')
for art in Article_list:
plt.plot(X_list, art.list, linestyle='solid', marker=".", label=art.label)
for _x,_y,_color in zip(mark_point_x,mark_point_y,mark_point_color):
plt.plot(_x, _y, linestyle='none', marker='D', color=_color)
plt.gca().invert_yaxis()
plt.grid(color='gray')
plt.legend(bbox_to_anchor=(1.02,1),loc='upper left',borderaxespad=0)
plt.subplots_adjust(right=0.7)
plt.xticks(date_place,date_list)
plt.yticks(range(1,bottom))
plt.show()
解説
表紙と巻頭カラーが一緒かどうかは単純に正規表現で解決しました。
if re.search('表紙(&|&)巻頭カラー',info.text):
今回のポイントはbeautifulsoup4での要素の取得。
前回は単純にタグ名を指定して全部を配列にして取得していたけど今回は一度classを指定してからそのクラスの中の任意の要素を指定して再検索する方法にしました。
この方法ができるようになったのはでかい。
beautifulsoup4のclassはTagとResult.setの2つがあって扱いが違うので結構大変でした。
同じ配列系でもアクセスの仕方が違うし…
info=(source.find_all("div",class_="info"))[1]
strongs=info.find_all("strong")
それから、前回示したグラフには地味に大きな問題があって独立したデータはグラフに描写されないという問題点を抱えていました。
たとえば、3月号と5月号が休載だった場合、4月号の掲載順は表示されません。
これは、データにマーカー(いわゆるグラフに打つ点)をセンターカラーにしかプロットしてなかったからで常にマーカーをプロットしてないと
独立したデータが見えないことに気がついたのです。(点と点を結んで線にしたときに初めて見える)
ただし、マーカーの種類は1種類しか指定できません。困りました。
そこで、以下のように全部の点に小さい点をプロットして、センターカラーのときはその上から新しく点をプロットすることにしました。
for art in Article_list:
plt.plot(X_list, art.list, linestyle='solid', marker=".", label=art.label)
for _x,_y,_color in zip(mark_point_x,mark_point_y,mark_point_color):
plt.plot(_x, _y, linestyle='none', marker='D', color=_color)
マークする点はまとめて1つの配列に入れて後から色を指定して区別を付けました。
color_cycle = plt.rcParams['axes.prop_cycle'].by_key()['color']
if art.is_centercolor(center_colors):
mark_point_x.append(index)
mark_point_y.append(i)
mark_point_color.append(color_cycle[color_index])
結果と考察
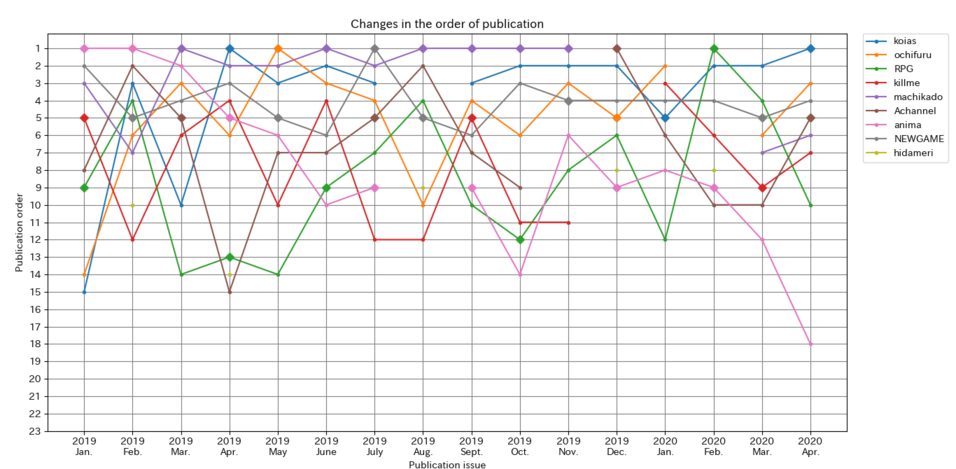
取得できたデータはこんな感じ。
↓キャラットの掲載順
ちゃんとひだまりの独立したデータも点で表示できている。
いい感じ。
グラフを眺めていてあることに気が付きました。
それは人気とかアンケートの結果に関係なく10番目に人気作品が置かれていることです。
10番目に来た作品は次の週で大幅に順位を上げるかセンターカラーに来ています。
MAXにもV字回復する点があります。それはセンターカラーです。
↓MAXの掲載順
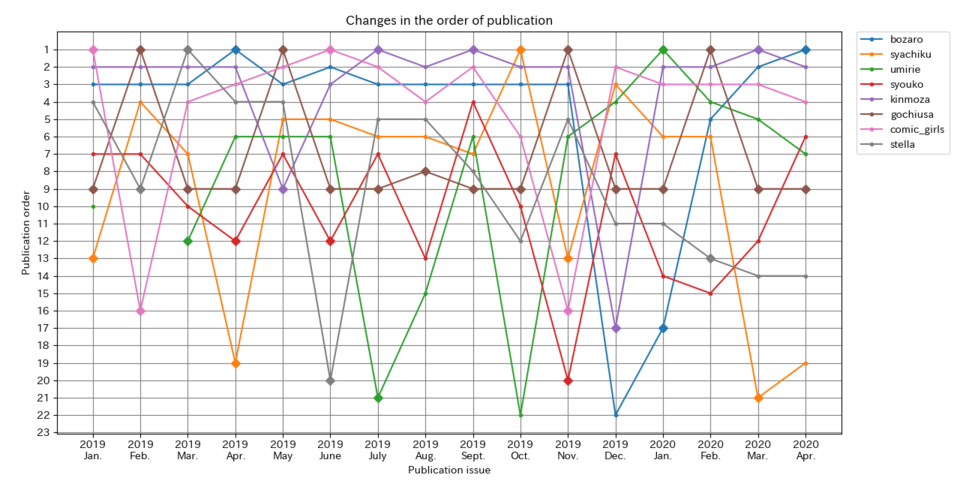
しかし、キャラットの10番目にはセンターカラーを示すダイアモンドの印はついていません。
これはキャラットにはセンターカラー以外にも定位置が存在するということでは無いでしょうか?
まぁだから?と言われればそうですが、単純にアンケートの結果で並べるんじゃなくて更に掲載順を工夫している気がするんですよね。
人気順だと途中で読むのやめちゃって多くの作品を読んでくれない可能性がありますから。
だからアニメ化されて人気のある作品を手頃な位置に定位置として置いてるんじゃないかと思うんです。(邪推)
ちなみにセンターカラーの回数はこちら。
Counter({
‘「アニマエール!」': 7,
‘「NEW GAME!」': 6,
‘「まちカドまぞく」': 6,
‘「RPG不動産」': 5,
‘「精霊さまの難儀な日常」': 5,
‘「異なる次元の管理人さん」': 4,
‘「Aチャンネル」': 4,
‘「ブレンド・S」': 4,
‘「メイドさんの下着は特別です。」': 4,
‘「魔王の娘からは逃れられない」': 4,
‘「あやしびと」': 4,
‘「キルミーベイベー」': 3,
‘「かぐらまいまい!」': 3,
‘「先パイがお呼びです!」': 3,
‘「恋する小惑星」': 3,
‘「紡ぐ乙女と大正の月」': 3,
‘「すわっぷ⇔すわっぷ」': 2,
‘「おちこぼれフルーツタルト」': 2,
‘「mono」': 2,
‘「まちカドまぞく」」': 1,
‘「かぐらまいまい!」': 1,
‘「ぐるメソッド!」': 1,
‘「はるみねーしょん」': 1,
‘「正義ノ花道」': 1,
‘「No Color!」': 1})
例によって表記ゆれとか担当者さんのタイポで正しくカウントできてませんね…
タイポとかどうやって対応すればいいんだ…
感想
ぷろぐらむ舐めてたら痛い目見た。(ぷろぐらむこわい)
まぁこれで今年の掲載順企画はおしまいかな。(購読してるのはMAXとキャラットだけだし)
今後はきららのデータベースサイトづくりに注力したいと思います。
データの取得については今回で調子を取り戻したし、MAXとキャラットについてはプログラムを流用できる部分もあるので良い準備運動になったかと思います。
成果物もいい感じにまとまっているし満足です。
むしろ成果をどう広めて行くかが今後の課題ですね。
いいものを作ってもそれ誰にも知られなければ意味がないですし、データを公開する理由があんまり無くなってしまいます。
まぁTwitterのフォロワーが少ないのが大きな原因ですかね。
この界隈の人間は自分を含めて、他人の発言より絵師のイラストを見たくてTwitterをやってるわけだし…(偏見)
難しいなぁ…
誰かRTして(懇願
まぁそういう広報活動もがんばります…