桃音ちゃんのお気持ちになって開発できるプログラミング言語"kinako-chan"を作った話
はじめに
この前TLでどうびじゅが完結して一周年だという話題が上がっていてもう一年経つのかという驚きと同時に
一年経っても未だに絵を書いてる人とか語っている人がいて同じどうびじゅが好きな人間として嬉しいなぁと感じます。
真に素晴らしい作品は例え月日が流れてもファンの間で語り続けられるんだなぁと感動しました。
なんて希望のある事実でしょうか。
感動しつつあれこれ考えながら過去のどうびじゅに関するツイートを色々見返していたんですがふとこんなツイートを見かけたんです。
きららMAX1月号の大人気連載、相崎うたう先生の「どうして私が美術科に!?」!今回はタイポグラフィの課題ということで、初めてのPCルームにはしゃぐX室メンバーです。しかし桃音さん、そのデザインは……。コミックス第1巻好評発売中!(https://t.co/a2r7QMa2pB) pic.twitter.com/CVzkRQdXom
— まんがタイムきらら編集部 (@mangatimekirara) November 16, 2017
みなさんご存知2巻のタイポグラフィ回です。(予告絵のカーソルで桃音ちゃんのほっぺをもちもちしてるやつ好き)
僕はその中のこのコマに着目しました。

そして僕は気がついてしまったのです…
もしもこの世に黄奈子ちゃんという言葉だけで構成されたプログラミング言語を開発したらこのコマの桃音ちゃんのお気持ちになってプログラムを書けるのでは?と。
おそらくこの行を読んで9割の人間がブラウザバックしたと思うので残りの1割の方はそのまま聞いてください。
だってしょうがないじゃないですか。そういう風に見えるんだもん。
もう僕には桃音ちゃんがプログラマにしか見えません。
僕だって桃音ちゃんがプログラムを書いてるところ見てみたいですよ。
でも僕は絵は書けないし聖典である原作にコラージュなんて恐れ多いことはできない。
なら現実を改変するしか無いじゃないですか。
こうなったら仕方ない。作りましょう。黄奈子ちゃん言語。
仕様策定
まずは言語仕様を決めましょう。(え?マジでやるの?とかいうツッコミは無しで)
最初は黄,奈,子,ち,ゃ,んの六文字の組み合わせにしようかと思っていたのですが、そうするとあの絵面にはならないなぁと思ったのでこの案はボツにしました。
唐突に'黄', '奈', '子', 'ち', 'ゃ', 'ん' の六文字を使ったプログラミング言語を開発したら桃音ちゃんをプログラマに仕立て上げることができるのでは?とひらめいてしまった
— 正弦工社 (@Seigenkousya) April 26, 2020
でもパターンを少なくすると今度はコードが以上に長くなって可読性が落ちるので「黄奈子ちゃん」という言葉と見た目の形はそのままに文字を微妙に変えて表現することにしました。
さてどうやって言語を実装しようかと悩んでいたのですが、単純な言語実装として有名なbrainfuckをベースにすることにしました。1
brainfuckは8個の命令からなる超小型のプログラミング言語です。大きな要素数を持ったuint8_t型の一次元配列とそれらの各要素を指すデータポインタによって構成されています。
各命令はこんな感じです。
| brainfuck | 意味 | C language |
|---|---|---|
| + | ポインタが指しているデータを1個増やす | (*ptr)++; |
| - | ポインタが指しているデータを1個減らす | (*ptr)–; |
| > | ポインタを右に1個ずらす | ptr++; |
| < | ポインタを左に1個ずらす | ptr–; |
| . | ポインタが指しているデータを出力する | putchar(*ptr); |
| , | 入力をポインタが指しているデータに代入する | *ptr=getchar(); |
| [ | ポインタが0なら次の]の1個右にポインタを移動させる | while(*ptr){ |
| ] | ポインタが0でないなら前の[の1個右にポインタを移動させる | } |
ポインタを操作して中身の数値を増減させながら目的の数値や文字を出力する感じです。
僕はまずこれを実装することからはじめました。(ちょうどやってみたかったし)
で、できたのがこれです。
とりあえずbrainf\*ckをベースにすることにしたのでインタプリタ兼ビジュアライザを実装してみた
— 正弦工社 (@Seigenkousya) May 1, 2020
あとはパースするトークンをいい感じに置換して終わり pic.twitter.com/NyfZF0oGVr
言語仕様が簡単なので実装もあっという間でした。なのでついでにビジュアライザ機能も付けてみました。
これを見ればある程度はこの言語のやっていることが分かるのでは無いでしょうか。
brainfuckのインタプリタ(プログラムを解釈して実行するプログラム)ができたのでbrainfuckが持っている8命令をそのまま自分の好きな言葉で置き換えれば黄奈子ちゃん言語が完成するということになります。
簡単ですね!(適当)
試行錯誤の末(結局確定するのに2日くらいかかった)仕様は以下のようになりました。
| kinako-chan | Meaning | brainfuck | C language |
|---|---|---|---|
| 黄奈子ちゃん黄奈子ちゃん | increment the data pointer | + | (*ptr)++; |
| 黄奈子ちゃん黃奈子ちゃん | decrement the data pointer | - | (*ptr)–; |
| 黃奈子ちゃん黄奈子ちゃん | increment the byte at the data pointer | > | ptr++; |
| 黃奈子ちゃん黃奈子ちゃん | decrement the byte at the data pointer | < | ptr–; |
| 黃奈子ちゃん黄奈孑ちゃん | output the byte at the data pointer | . | putchar(*ptr); |
| 黃奈子ちゃん黃奈孑ちゃん | accept one byte of input | , | *ptr=getchar(); |
| 黄奈子ちゃん黄奈孑ちゃん | jump to ‘黄奈孑ちゃん黄奈子ちゃん’ if the byte at data pointer is zero |
[ | while(*ptr){ |
| 黄奈孑ちゃん黄奈子ちゃん | jump to ‘黄奈子ちゃん黄奈孑ちゃん’ if the byte at data pointer is zero |
] | } |
最終的な仕様書はここから見られます。
よく見るとそれぞれの命令が少しずつ異なっています。内部のデータが違ければなんでもいいんのでなるべく近い見た目のものを選定しました。
黄と黃、子と孑の4つの組み合わせが2つあるので理論上はbrainfuckの二倍の16命令を持つことができます。
この記事の執筆時点でのバージョンは1.0.2 1.0.3ですが、命令はbrainfuckと同様に8個です。これから拡張するかも知れません。
できたもの
いつもならここで長々と技術的な話をするのですが、それをやると知らない人はつまらないと思うので先に成果物を見て貰いましょう。
その方が技術的な話をするときにも想像しやすいですしね。
デモの動画がこちらになります。
桃音ちゃんのお気持ちになってプログラムを書きたくなったのでプログラミング言語kinako-chanを開発しました#doubiju pic.twitter.com/zm17APApYH
— 正弦工社 (@Seigenkousya) May 6, 2020
なかなかいい感じです。
ターミナルの文字数に合わせて表示する文字数を変えているのもちゃんと動いてる。
これはなかなか桃音ちゃんのお気持ちになってプログラムがかけます。
大量の黄奈子ちゃん成分を補給することもできて一石二鳥です。
素晴らしいですね。
kinako-chanをはじめよう
レポジトリのREADMEにも書いてますがkinako-chan入門をさらに噛み砕いてここに書いてみたいと思います。
一応、ある程度知識がある人を想定して書いてます。
Unix初心者から中級者くらいですかね。
OSはLinuxとMacに対応しています。(Macの方は確認待ちだけど)
まずインストールにはgitを使います。
$ git clone https://github.com/Seigenkousya/kinako-chan.git
Cloning into 'kinako-chan'...
remote: Enumerating objects: 132, done.
remote: Counting objects: 100% (132/132), done.
remote: Compressing objects: 100% (83/83), done.
remote: Total 409 (delta 80), reused 94 (delta 47), pack-reused 277
Receiving objects: 100% (409/409), 301.91 KiB | 640.00 KiB/s, done.
Resolving deltas: 100% (243/243), done.
kinako-chanというディレクトリができるので移動します。
$ cd kinako-chan/
最後にmakeしてインストールします。
$ make install
g++ -g -O0 -I./include -o src/obj/display.o -c src/display.cpp
g++ -g -O0 -I./include -o src/obj/code_check.o -c src/code_check.cpp
g++ -g -O0 -I./include -o src/obj/main.o -c src/main.cpp
g++ -g -O0 -I./include -o src/obj/process.o -c src/process.cpp
g++ -O2 -o ./kinako-chan src/obj/display.o src/obj/code_check.o src/obj/main.o src/obj/process.o
これでkinako-chanというファイルができたらOKです。
サンプルとしてexample.knkというファイルがあるので試しに実行してみましょう。
$ ./kinako-chan example.knk
動いたでしょうか?ビジュアライズされて表示されたかと思います。
でもいつもこれだと時間がかかります。
結果だけ欲しいときは以下のようにします。
$ ./kinako-chan -n example.knk
hello world
hello worldをやってみましょう。 hello worldは以下のように書きます。
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈孑ちゃん
黃奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黃奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黃奈子ちゃん黃奈子ちゃん黃奈子ちゃん黃奈子ちゃん黃奈子ちゃん
黃奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん
黃奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黃奈子ちゃん黄奈孑ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黃奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黃奈子ちゃん黃奈子ちゃん
黃奈子ちゃん黃奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黄奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん
黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黃奈子ちゃん黄奈孑ちゃん
黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん
黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈子ちゃん黃奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黃奈子ちゃん黄奈子ちゃん
黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん黃奈子ちゃん黄奈子ちゃん黄奈子ちゃん黄奈子ちゃん黃奈子ちゃん黄奈孑ちゃん
これをhello_world.knkとして保存して、
$ ./kinako-chan -n hello_world.knk
hello world!
として実行するとhello world!の結果が得られると思います。
これで入門完了です。
実装
というわけで実装の話です。
仕様が決まれば後はもう実装するだけです。(技術的な話が続くので興味ない人は"kinako-chanの今後"の章まで飛ばしてください)
リポジトリはこちら。
何で実装しようか迷ったんですが勉強も兼ねてC++で実装することにしました。
日本語(というより2byte文字)の扱いが難しい言語ですがこれも勉強です。
僕はC++を書こうとするとC言語にどんどん近づいていく癖があるのでそれを封印するのが大変でした。
早くこれになりたい。

C++における日本語の扱い
「黄奈子ちゃん」は日本語なので普通のASCII文字(いわゆる半角)とは扱いが違います。char型では扱えません。
最初はchar *型でバイナリレベルで比較すればいいかってなったんですがそれだとビジュアライザを作るときに厄介になるのでちゃんと文字列型で取ることにしました。
C++の場合はstd::stringではなくstd::wstringを使って文字を表します。
いわゆるワイド文字の扱いをするわけです。ここで厄介なのがロケールの問題。
出力先の文字コードがわからないと上手く表示できないので予めコード内で設定する必要があるのです。
#include <iostream>
#include <string>
int main(void){
std::locale::global(std::locale(""));
std::wstring hello=L"日本語の出力";
std::wcout << hello << std::endl;
return 0;
}
ここで結構詰まった…
また、std::coutとstd::wcoutは混在すると出力がバグってかなり厄介になります。
はっきり言って地獄です。
なので今回は出力ストリームをstd::wcoutに統一しました。(出力ストリームの混在が不可能だと知って途中で変えたので大変だった)
あわせて出力に関わるすべての文字列型をstd::wstringにしました。(少々もったいないですが)
処理の大まかな流れ
kinako-chanは今のところインタプリタで動作する言語です。
実行ファイルを吐いたりはせずその場で結果を出力します。
$ ./kinako-chan terget_file.knk
みたいな感じでファイル(拡張子は.knk)を引数に与えて実行します。
デフォルトではビジュアライズ機能もついていてどのコードの部分でどのようにデータが操作されているのかを見ることができます。
それでは大まかな処理の流れを見ながら解説していきましょう。
1.オプションの確認
インタプリタkinako-chanは様々な引数を取るのでそれを最初に確認してオプションごとに分岐してます。
といってもargcの個数を確認して条件分岐をしてargvをstrcmpしてるだけですが。
オプションごとにflagを書き換える感じで素直に実装してます。
2.ファイル読み込み
引数にファイルをとっているのでそれをstd::wstringに代入して処理しています。
// read file
std::wifstream file(filename);
if(!file){
std::wcerr << L"failed to open file." << std::endl;
std::exit(1);
}
// get stiring
std::wstringstream wss;
wss << file.rdbuf();
std::wstring source=wss.str();
失敗したらエラーコードを吐かせるのを忘れずに。
普通に処理すると行ごとの取得になってしまうので一度すべてstd::wstringにぶちこむのがポイント。
3.コードを整形
コード整形と構文の確認をします。
具体的にはkinako-chanで採用している「黄,奈,子,ち,ゃ,ん,黃,孑」以外の文字(改行を含む)を除外します。
void syntax_check(std::wstring& source){
int index=0;
std::wstring tokens=L"黄奈子ちゃん黃孑";
while(index!=source.size()){
if(tokens.find(source[index])==std::wstring::npos){
source.erase(index,1);
}else{
index++;
}
}
if(source.size()%12!=0){
std::wcerr << L"undefined token." << std::endl;
}
}
それからトークンの文字数があっているかなどの軽い構文チェックもしてます。(といっても文字数によるチェックだけですが)
そうすると後々の処理がかなり楽になります。
オプションによってはここでコードを変換した後結果を出力して処理を終了させます。
それから与えられたコードを中間コード(brainfuck)に変換します。
なぜこれをやるかと言うとビジュアライザの機能の方でbrainfuckに変換したコードを表示するからという合理的な理由と
既にbrainfuckのインタプリタとビジュアライザを作ってあるのでここで変換しておくと関数が流用できるというゲスい理由があります。
4.処理
ついに処理です。
メモリを確保して命令に従ってデータポインタと数値を操作します。
配列は有限なのでデータポインタが配列の外側に行ってないかポインタを移動させる前に確認させます。
void within_range(uint8_t *now){
if(now-head<0 || now>head+MEMORY_SIZE){
std::wcerr << L"now:" << now << L" head:" << head << std::endl;
std::wcerr << L"now-head:" << (int)(now-head) << std::endl;
std::wcerr << L"point out of range." << std::endl;
std::exit(1);
}
}
uint8_t型の配列なので255を越えても変な値にならず0になります。(安全性の確保)
一度処理をするごとにデータを画面に表示します。
5.データと結果の表示
デフォルトではビジュアライザの機能がオンになっていて20msごとに命令が解釈されて画面に表示されます。
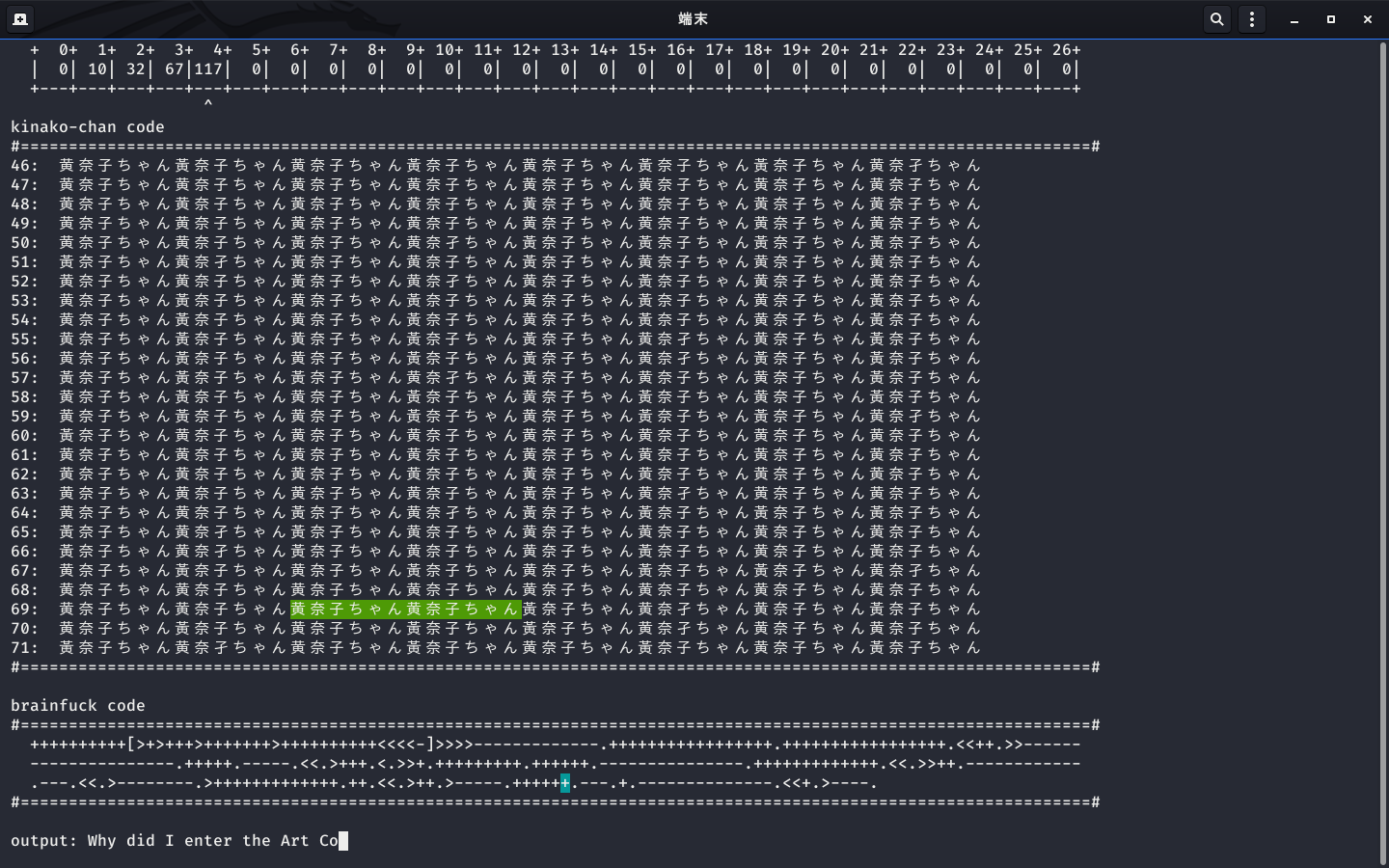 ここが一番実装に時間をかけた処理かも知れません。
ここが一番実装に時間をかけた処理かも知れません。
難解な言語なのでこの機能は必須です。
表示するデータとして
- メモリの状態
- データポインタの位置
- kinako-chanの現在実行しているトークン
- brainfuckに置き換えたときのコードと現在実行しているトークン
- 出力された文字
を表示しています。
基本的にはシステムコマンドで画面をクリアしてエスケープシーケンスで画面をクリアしてカーソルを移動してAAでデータを描画している感じですね。
実行しているトークンには色付け表示もしました。
実行するコードが最後まで行くとプログラムが自動で止まって終わりです。
開発手法の話
今回は開発手法の方にも力を入れました。(実装自体は難しくないのでここら辺の挑戦もした)
言語開発なので正式な手順を踏んでやりたかったのです。
ファイルの構造化
最初は一つのファイルに書いていたのですがこれでは保守性が下がるのでプログラムを以下のように分割しました。
.
├── LICENSE
├── Makefile
├── README.md
├── example.bf
├── example.knk
├── include
│ └── kinako-chan.h
├── kinako-chan
└── src
├── code_check.cpp
├── display.cpp
├── main.cpp
├── obj
│ ├── code_check.o
│ ├── display.o
│ ├── main.o
│ └── process.o
└── process.cpp
機能ごとにファイルを分けてヘッダファイルとソースとオブジェクトファイルを別の階層に置きました。
正直ここまでちゃんとソースを階層に分けたのは初めてです。
これでだいぶ見た目がスッキリしてメンテナンスが容易になりました。
これに合わせてMakefileも書き換えることに。(エラーが多発して結構詰まった)
Makefileのいい練習になりました。
ブランチの有効活用
いつもはついmasterで作業しがちですが、途中で煩わしくなってちゃんとブランチを切るようにしました。
具体的には、
master: 本番環境。mergeによってのみ更新。
develop: 基本開発はここ。ここから作業ごとにブランチを切る。
fix: 今回は使わなかった。issueごとに切ることになると思う。
fix: めっちゃ使った。develop or masterから分岐してバグを直す。図らずとも大活躍してしまった。
ver x.x.x: バージョンごとに切る。
って感じ。その他にも作業の内容でdevelopから切ったこともあった。
今回はcloneされる前提で開発する必要があるのでちゃんとブランチを切らないと作業途中のところでダウンロードされる可能性があるんですよね。
今までみたいにmasterで作業するわけには行かない。
これからもこのルールは守って開発して行きたいです。
恩恵としてはブランチ名を決めることでやることが明確になることと衝突を避けられるということでしょうか。
Travis CIの活用
今回試して一番大きかったのはこれです。
travis CIとは、githubと連携してpushする度に自動で仮想環境にレポジトリをcloneしてビルドテストとこちらで指定したテストスクリプトを実行してくれる無料の素晴らしいサービスです。
環境は複数してできてosxとlinuxでg++とclang++のそれぞれをビルドテストしてます。
基本的にコマンドは(インストールされていれば)受け付けてくれるのでシェルスクリプトなどでテストコードを書いておけば実行してくれます。
自動でテストを行ってくれるので後々こんなこと2に
なることを防ぐことができます。
いわゆるCIと呼ばれる手法を実現するためのサービスで日本語では継続的インテグレーションと呼ばれています。
頻繁に複数のコミットを一つのブランチに自動でテストしてビルドしてマージするという工程の繰り返しで開発が進んでいきます。
今回は完璧にこの考えに則って開発したわけではありませんが自動的に複数の環境でテストを行えただけでも大きかったと思います。
おかげで何個もバグに気付けましたし持ってないmacOSにもなんとか対応できました。
これが無料なんてすごいですね。(ソフトウェア界隈はこういうサービスがことごとく無料でありがたい)

ドキュメントの充実
ちゃんとした言語なのできちんとドキュメントを書こうと決めました。(まだ不十分だけど)
バージョンやビルドテストのバッチを付けたり言語仕様を書いたり…
こういうのはエンジニア界隈では基本的に英語です。英語が不自由なので辛かった…
Makefileのおかげでインストール方法も簡潔になってちゃんと書いておいて良かったなと思いました。
えーーーー!@Seigenkousyaの担当箇所がバグだらけ!?
はい。(はいじゃねぇよ)
えーーーー!@Seigenkousya の担当箇所がバグだらけ!?
— 正弦工社 (@Seigenkousya) May 6, 2020
やってしまいました。
懸念していたmacOSの表示関係がドンピシャでOUTです。
手元に環境がなくて不安だったのですが使ってくださった方が報告してくださって早めに気づくことができました。(ありがとうございます)
さて、手元に環境が無い(構築不可)上に頼みのTravis CIは画面クリアなど表示系の部分まで対応していません。
どうやらエスパー3でバグを治す必要があるようです。(地獄)
どちらもmacOSでのバグだったのでこちらのlinuxで動いている以上OS依存の問題だということになります。
kinako-chanの内部システムでOS依存の処理だと考えられるのは次の3つです。
- 画面をクリアする
"\033c" - ウィンドウのサイズを取得する
ioctl(STDOUT_FILENO,TIOCGWINSZ,&size); - wstringの出力文字コードを指定する
std::locale::global(std::locale(""));
最初に疑ったのは画面クリアの処理です。
フレームが残っているということは画面を正常にクリアできていないということである
— 正弦工社 (@Seigenkousya) May 6, 2020
エスケープシーケンスまわりが原因か?
brainwash: std::system("clear")
kinako-chan: L"\033c"
上手く表示ができないならちゃんと画面をクリアできてないのではと考えました。
実際、画面消去に使っていたエスケープシーケンスである"\033c"はKDEのコンソールで動かない問題があったのですが、直接の原因ではありませんでした。
結局ここで多くの画面消去法を試してみましたが結局確かめようが無いので色々考えていました。
そして遂にひらめきました。
分かった!(超速理解)
— 正弦工社 (@Seigenkousya) May 6, 2020
ターミナルのsetlocaleがmacとlinuxで違う(多分)から2byte文字に入る最初の「黄奈子ちゃん」で躓いて止まるんだ
超速理解(激遅理解)
よくよく送られたスクリーンショットを見てみると、どちらも最初の「黄奈子ちゃん」を描画しようとする部分で出力が止まっています。
これでようやく気づきました。日本語の出力方法に問題があって止まっていたのです。
setlocaleは環境によってはかなり設定するのが厄介なのでおそらくここだと目星を付けました。
あとはエスパーしてmacで動きそうな方法を選んで修正しました。(2行追加)
+ std::ios_base::sync_with_stdio(false);
std::locale::global(std::locale(""));
+ std::wcout.imbue(std::locale(""));
今思えばよくこんなあっさり手元にない環境に対応したコードをかけたな…(エスパーデバッガーの才能あり?)
朝見たらどうやらちゃんとmacOSでも動くようになったようです。
めでたしめでたし。
修正版をver 1.0.3としてリリースしました。
今回の一件で複数の環境に対応させる大変さを知りました。(持ってない環境なら尚更)
本当に今回ご協力頂いた両名に改めて感謝します。ありがとうございました。
これからにも役立ついい経験になったかなと思います。
kinako-chanの今後
今後実装したい機能として、
- 残りの8個の命令を策定して実装(せっかく8つ余っているので)
- kinako-chanで何か実装する
- コンパイラを作る(コンパイラ言語として対応)
- wikiを作成する(さらなる仕様の策定)
- OSS化
- Webで動くインタプリタを作る
- osx + g++ の組み合わせに対応する(clang++が前提だが一応)
などが挙げられます。
今やってる自作Cコンパイラを書き上げたらまたやってみたいですね。
これからも少しずつ開発はやってみたいと思います。
FAQ
[Q] 頭大丈夫ですか?
[A] 大丈夫です。
[Q] お医者さんからもらったお薬飲んでますか?
[A] ちゃんと飲んでますよ。虹色のやつ。
[Q] kinako-chanはチューリング完全ですか?
[A] ベースとなっているbrainfuckがチューリング完全なのでkinako-chanもチューリング完全です。
[Q] kinako-chanを使ってゲームは作れますか?
[A] 作れます。十分なサイズの配列を確保できれば理論上は可能です。
[Q] プログラムの改変は可能ですか?
[A] MITライセンスで配布しているため大丈夫です。forkも歓迎です。
[Q] プログラムが動かない。バグが見つかった。
[A] @SeigenkousyaのTwitterまでご連絡ください。
[Q] 開発に参加できますか?
[A] もちろんです。無言でプルリクとか送ってくださって全然大丈夫です。
[Q] 今後命令拡張はありますか?
[A] 残りの8命令を実装することは考えています。その場合、互換性が保たれるように設計します。
[Q] 芳文社に怒られたりしないんですか?
[A] ……
最後に
久しぶりにこういうことやった気がします。(相崎先生ごめんなさい)
どこからか狂気を感じるという声が聞こえてきそうですが、これも情報科学の発展のためです。
嘘です。でも知的欲求を満たせたのは事実なのでそこは良かったです。
動機に反してかなり理性的に開発ができました。
これ程真面目で教科書どおりに開発を行ったのは初めてです。
これからは桃音ちゃんのお気持ちになってこの言語で開発をしようと思います。
みなさんもこの言語で桃音ちゃんのお気持ちになりましょう。
それではさようなら。
-
そういうプログラミング言語があるんです。
https://ja.wikipedia.org/wiki/Brainfuck ↩︎ -
実際企業のプロジェクトでやるときはどうするんだろう。
外部のサービスを使うわけにも行かないだろうし。やっぱり内部で構築するのかな? ↩︎ -
要は勘です。肝心なのは祈り。 ↩︎